智能时代软件开发新范式 数据工程、自动化评估与知识图谱在大模型研发中的融合
在人工智能技术飞速发展的当下,大模型已成为推动产业智能化转型的核心引擎。其研发不再仅仅是算法与算力的竞赛,更演变为一项涉及数据、评估与知识融合的系统性工程。本文将深入探讨大模型研发的核心支柱——数据工程、自动化评估体系及其与知识图谱的深度结合,如何共同塑造新一代软件开发的范式。
一、数据工程:大模型研发的基石
高质量、大规模、多样化的数据是训练出强大模型的先决条件。现代数据工程已超越传统的数据收集与清洗,演变为一个全生命周期的系统工程:
- 数据策划与生成:针对特定领域或任务,进行系统的数据需求规划。在高质量标注数据稀缺的领域,利用数据合成、增强技术(如Diffusion模型生成图像、文本回译与重构)来扩充数据集,或设计高效的主动学习策略以降低标注成本。
- 数据治理与质量保障:建立严格的数据质量标准,包括准确性、一致性、多样性与公平性。通过自动化工具进行数据去重、去噪、偏见检测与修正,确保训练数据的纯净与均衡。
- 高效数据处理流水线:构建可扩展、自动化的数据处理管道,实现从原始数据到模型可读格式的高效转换与管理,支持持续的数据迭代与版本控制。
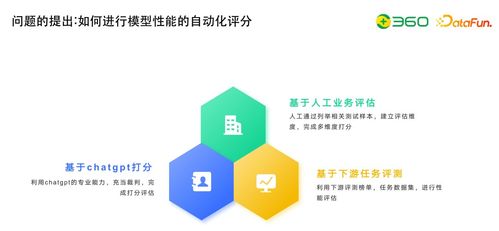
二、自动化评估:模型迭代的导航系统
随着模型规模扩大与能力复杂化,传统的人工评估已无法满足高效迭代的需求。自动化评估体系成为关键:
- 多维评估基准构建:建立涵盖通用能力(如MMLU、BIG-bench)、领域专业能力(如医学、法律、代码)、安全性、偏见性、推理能力等多维度的标准化评测集。
- 评估流程自动化:开发自动化评测框架,能够对模型进行批量、持续的测试,快速生成全面的评估报告(如准确率、鲁棒性、延迟、成本等指标)。
- 基于评估的反馈优化:将评估结果直接反馈至训练流程,指导数据混合策略、超参数调整或强化学习中的奖励函数设计,形成“评估-优化”的闭环。
三、知识图谱的深度融合:赋予模型结构化的“思想骨架”
大模型虽拥有强大的参数化知识,但在事实准确性、逻辑推理和可解释性上仍面临挑战。知识图谱(KG)作为结构化的语义知识库,能与之形成强大互补:
- 增强事实准确性与可追溯性:将知识图谱作为外部事实源,供模型在生成时检索与引用(即检索增强生成,RAG),显著提升回答的准确性,并提供知识来源,增强可信度。
- 提升复杂推理能力:利用知识图谱中实体间的显式关系(如因果、时序、层级),引导或约束模型进行更符合逻辑的链式推理和规划,弥补大模型在深层推理上的不足。
- 驱动专业化与领域适配:将领域知识图谱(如金融风控图谱、生物医学图谱)与大模型结合,能快速构建高质量的专业领域助手,实现知识的深度理解和应用。
- 优化模型训练与对齐:将知识图谱中的结构化知识作为高质量监督信号,用于预训练或微调阶段,帮助模型更好地学习关系与逻辑;也可用于对齐过程,确保模型输出符合人类价值观和领域规则。
四、融合驱动下的软件开发范式演进
上述三者的结合,正在深刻改变软件开发的方式:
- 开发重心转移:从精细化的特征工程和算法设计,转向对数据生态、评估体系及知识融合架构的宏观构建与管理。
- 流程智能化与自动化:形成了“高质量数据供给 -> 自动化训练与评估 -> 知识增强与纠错”的智能化开发流水线,大幅提升研发效率与模型质量。
- 应用形态升级:催生出新一代AI应用——它们不仅“能说会道”,更能基于精准的数据和结构化的知识,提供可靠、可解释、可追溯的决策支持与服务,如智能顾问、自动化研发助手、精准营销系统等。
大模型的竞争,本质上是其背后整个研发与支撑体系成熟度的竞争。数据工程、自动化评估与知识图谱的结合,构成了这一体系的核心三角。它们共同确保了大模型从“规模庞大”走向“能力强大”与“应用可靠”。三者更深度的无缝集成与自动化,将是释放大模型全部潜能、构建真正智能软件系统的关键路径。对于软件开发者和企业而言,掌握并驾驭这一新范式,是在智能化浪潮中保持竞争力的核心所在。
如若转载,请注明出处:http://www.booksirsoft.com/product/73.html
更新时间:2026-02-24 03:55:43